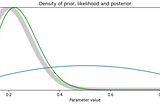
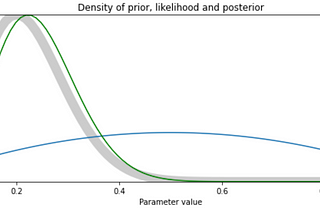
Mithun GhoshIntro to Bayesian StatisticsIn statistics and probability theory we tend to model natural phenomena and try to predict unforeseen circumstances. It's about making…10 min read·Mar 10, 2021----
Mithun GhoshMeasurement Metrics for ML model evaluationIn today’s world we have abundance of data being generated from various systems. These data are the footprints of various system…10 min read·Mar 3, 2021----
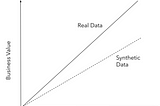
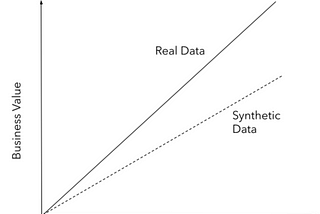
Mithun GhoshSynthetic Data GenerationGet your business the maximum value using data science in most challenging scenerio when you don’t even have data6 min read·Feb 22, 2021----
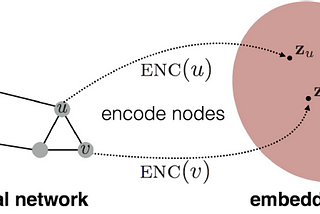
Mithun GhoshDeep Learning for GraphsGraph data structure is a versatile way of representing relational information. It has some nice mathematical properties which allows us…6 min read·Feb 19, 2021----